Задачи
за смеси
Задачи за смеси и линейно независми променливи
Обратно
към въвеждане на данни
Планиране
на експерименти със смеси
QstatLab
позволява да се построят следните видове планове за
смеси:
-
Симплексни решетки на
Шефе -
SCHEFFE
-
Симплекс центроидни
планове -
CENTROID
-
Планове с двустранни
ограничения на компонентите (известни още като планове на Мак-Лийн и
Андерсън) -
EXTVERT
-
План със случайно
генерирани точки в симплексното пространство –
RANDMIX
-
Псевдокомпоненти в
случаите когато ограничената област е също симплекс, зададен с върховете
си.
За всички видове планове най-напред се избира
опцията

Появява се таблицата за
избор, в която се маркира прозорчето „Смеси“:

Изборът
е на един от видовете планове:

Начало
Построяване
на симплексни решетки
При
избор на метод се маркира „SCHEFFE:
Симплексна
решетка (Шефе)“. Избира се брой зависими променливи и ред на модела. Възможни
са следните съчетания (в таблицата е посочен броят на опитите за съответния план).
Брой опити при различен брой линейно зависими
фактори и ред на модела
(без централна точка)
|
Фактори -->
Ред на модела
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
1
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
2
|
6
|
10
|
15
|
21
|
28
|
36
|
45
|
55
|
66
|
78
|
91
|
105
|
120
|
|
3
|
10
|
20
|
35
|
56
|
84
|
120
|
165
|
220
|
286
|
364
|
455
|
560
|
680
|
|
4
|
15
|
35
|
70
|
126
|
210
|
330
|
495
|
715
|
991
|
1365
|
|
|
|
|
5
|
21
|
56
|
126
|
252
|
462
|
792
|
1287
|
|
|
|
|
|
|
|
6
|
28
|
84
|
210
|
462
|
924
|
|
|
|
|
|
|
|
|
|
7
|
36
|
120
|
330
|
792
|
|
|
|
|
|
|
|
|
|
|
8
|
45
|
165
|
495
|
1287
|
|
|
|
|
|
|
|
|
|
|
9
|
55
|
220
|
715
|
|
|
|
|
|
|
|
|
|
|
|
10
|
67
|
286
|
1001
|
|
|
|
|
|
|
|
|
|
|
Забележки:
-
Ако се добави централна
точка броят на опитите се увеличава с 1
-
В таблицата са дадени
само планове, броят на опитите за които
e
около 1000. Програмата може да генерира и планове с
повече от 1000 опита, но те са непрактични.
-
Ако броят на опитите е
твърде голям, той може да се намали като се използва процедурата за
генериране на
D-оптимални
планове и от плана се избере брой точки, зададен от оператора (N
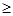 k).
k).
Пример.
Желаем да построим симплексна решетка от ред
n
= 2 за пет компоненти на сместа (q=5).
-
Кликваме
иконката
 и правим
следните настройки:
и правим
следните настройки:

-
Кликваме
„Преглед“ и се появява таблицата за съставяне на плана. Кликваме „Старт“ и
в таблицата се появява желаният план:
Той може да се копира
( ),
рандомизира
(
),
рандомизира
( ), записва във файл
(
), записва във файл
( ) и пренася в
основната таблица (
) и пренася в
основната таблица ( )
)
Начало
Построяване
на симплекс центроидни планове
-
Избира
се
 и след това:
и след това:

При този вид планове броят на компонентите
(зависимите променливи) винаги е равен на реда на модела. Броят на опитите
зависи от реда на модела както следва:
|
Фактори
|
2
|
3
|
4
|
5
|
6
|
7
|
|
Опити
|
3
|
7
|
15
|
31
|
63
|
127
|
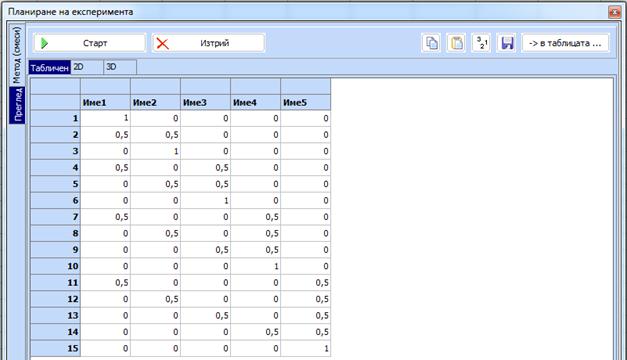
-
Кликва
се „Преглед“ и след кликване на „Старт“ се появява желаният план:
Начало
Построяване
на планове при двустранни ограничения на компонентите (планове на Мак Лийн и
Андерсън)
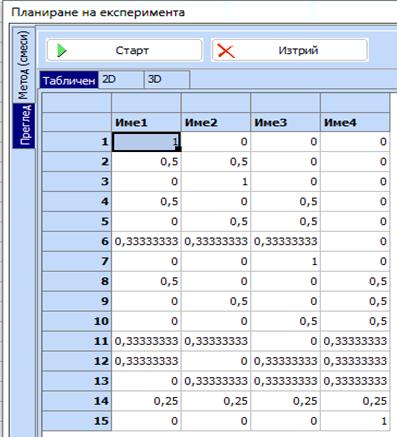
-
Избира
се и след това:

-
Кликва
се бутона „Нива“ и се задават ограниченията:
-
Кликва
се „Преглед“, след това „Старт“ и се получава желаният план:
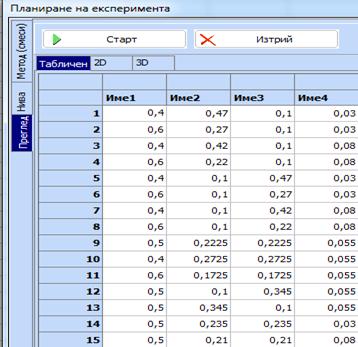
Начало
Генериране
на случайни точки в симплекса
При
някои планове може да пожелаем да добавим случайни точки в симплексното
пространство, като ги използваме като контролни опити. Изискването е
координатите им да се подчиняват на условието:
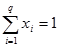
Генерирането
на случайни точки става с процедурата
RANDMIX:
Случайни точки в симплекса. Нека например да имаме задача с 5 компоненти и да
искаме да генерираме 7 случайни точки, които да използваме като контролни
опити.
1.
Избира се
и
след това

2.
Отива се на „Преглед“ и след кликване на
„Старт“ се появяват координатите на случайните точки:
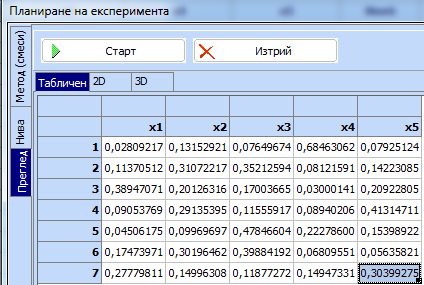
Сумата
на компонентите във всеки от редовете е равна на 1.
Начало
Обратно
към въвеждане на данни
Регресионен
анализ при експерименти със смеси
За
компонентите на сместа са в сила следните условия:
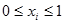 за
за
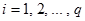 и
и
Това
води до следните особености на приложението на процедурата на регресионния
анализ:
·
Използват се приведени регресионни модели. В
тях липсва свободен член и няма фактори на втора или по-висока степен. Има
произведения на фактори:
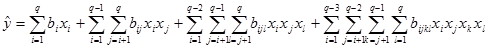
QstatLab
дава
възможност да се построяват модели, включващи всички линейни членове и
произведения на факторите до 4 ред от типа
·
Симплексните решетки и симплекс центроидните
планове са наситени планове т.е. при тях броят на опитите е равен на
броя на коефициентите
(N=k).
Поради това само тези опити не позволяват да се извърши статистически анализ на
регресионния модел. Затова се препоръчва добавянето на допълнителни
(„контролни“) опити в пространството, които се избират по усмотрение на
потребителя. С тях броят на опитите става по-голям от броя на коефициентите (N>k)
и това прави статистическия анализ възможен. Процедурата за извеждане на
регресионните модели при симплексни решетки и симплекс центроидните планове е
еднаква.
·
Плановете с двустранни ограничения на
компонентите (планове на Мак Лийн и Андерсън) обикновено имат повече опити от
броя на коефициентите в модела (N>k).
Това прави ненужно добавянето на нови „контролни“ опити.
·
Когато
в задачата има както компоненти на сместа (зависими фактори), така и
независисми фактори, които се изменят незавсисимо в граници от -1 до 1 се
използва друг вид приведени модели. Ако полиномът е от втори ред той не включва
свободен член, квадрати на компонентите на сместа и линейни членове за
независимите променливи. За
q
компоненти
на сместа и r
променливи
(общо
m = q + r
фактора) този вид модели изглежда
така:
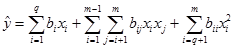
Пример
за регресионен анализ, построяване на графики и оптимизация при използване на
симплексна решетка
Изследва
се смес за протектор на тежка конвенционална гума в зависимост от 4 фактора: Булекс
1500 ( x1 ), Булекс М-27 ( x2 ), СКИ-3 ( x3 ), СКД (
x4 ). Останалите
компоненти са поддържани на постоянни нива. Изследват се 4 свойства на гумата
със следните изисквания:
|
Свойство
|
Y
|
Размерност
|
Изискване
|
|
Изтриваемост
(Континентал)
|
у1
|
mm^3
|
>100 |
|
Якост
при опън
|
у2
|
kg/cm^2
|
>150
|
|
Якост
при раздир
|
у3
|
kg/cm^2
|
>80
|
|
Динамичен
модул
|
у4
|
kg/cm^2
|
>80
|
Планът
на експеримента и резултатите от опитите са дадени във файл
Mixtures-tezhki_gumi.qsl
от
директорията Primeri (намира се в директорията в
която е инсталиран продуктът):
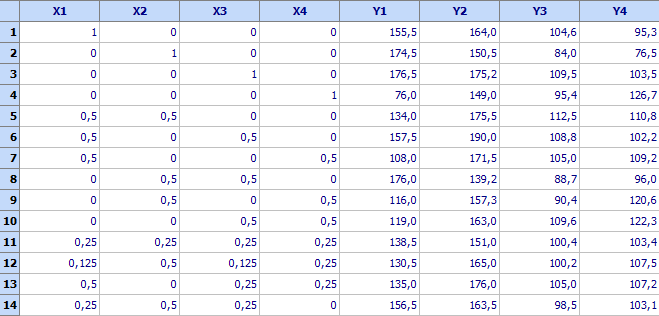
Първите 10 опита са
симплексна решетка, а останалите 4 са добавени от потребителя „контролни
опити“. За построяване на регресионен модел за у1 се извиква процедурата
за регресионен анализ  и след въвеждане на данните
се избира модел. За целта се маркира полето пред надписа „Смеси“. Така
програмата се инструктира за избере подходящ за смесите модел.
и след въвеждане на данните
се избира модел. За целта се маркира полето пред надписа „Смеси“. Така
програмата се инструктира за избере подходящ за смесите модел.
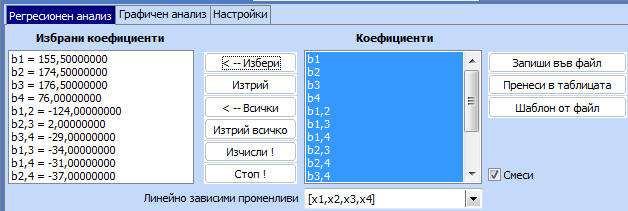
След
избора на модела се получава следния резултат:

Коефициентът
на множествена корелация е значим (p
= 0,00059 < 0,05), но моделът съдържа голям брой незначими коефициенти.
Изчистваме ги един по един, като започнем от тези с на-голяма стойност на р. Получава
се следният модел:
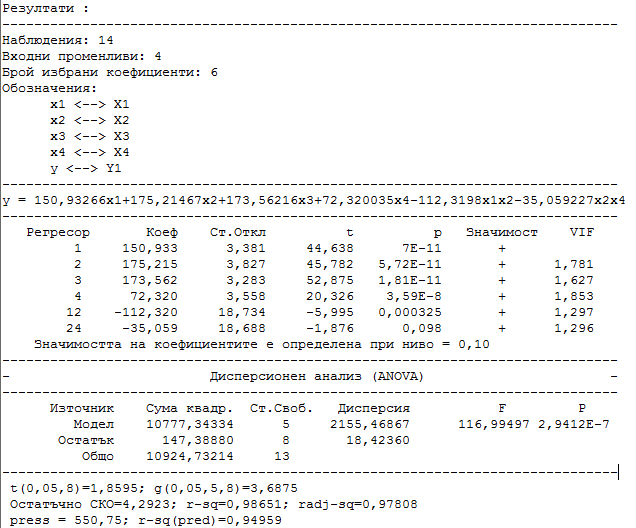
С
бутона  прехвърляме получения модел
в таблицата с данните. По подобен начин са получени моделите и
за останалите три свойства.
прехвърляме получения модел
в таблицата с данните. По подобен начин са получени моделите и
за останалите три свойства.
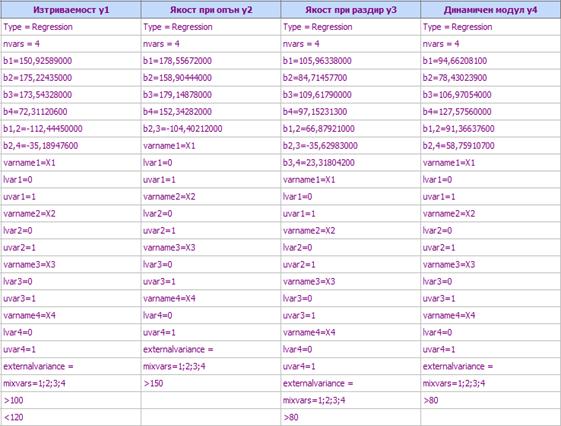
След
пренасянето на модела най-отдолу автоматично се добавя един ред, в който се
посочва кои фактори са линейно свързани:
 .
Ако
има ограничение, то също се нанася най-отдолу
.
Ако
има ограничение, то също се нанася най-отдолу
Начало
Обратно
към въвеждане на данни
Графична
интерпретация (линии на постоянни стойности)
Получените
модели могат да се използват за начертаване на триъгълни диаграми, описващи
дадено свойство (с или без ограничения). Това са трикомпонентни диаграми затова
в задача като разглежданата, която е с 4 компоненти, на някоя от компонентите
трябва да се зададе на постоянна стойност. Ще начертаем диаграмата на у1 по
компонентите х1, х2, х3 при условие х4 = 0 при зададените ограничения за
у1,у2,у3,у4. За целта кликваме иконката
 след
което дефинираме целевата функция и ограниченията:
след
което дефинираме целевата функция и ограниченията:
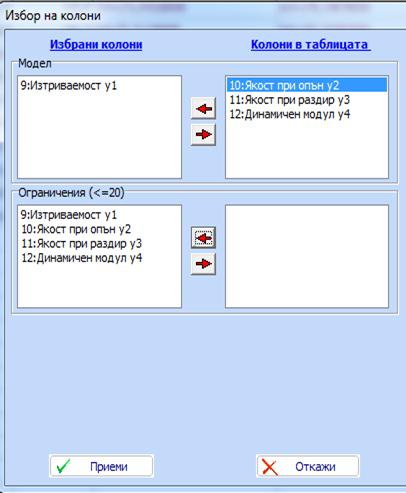
Кликваме „Приеми“ и се появява диаграма при
X4
= 0. Настройките са избрани автоматично както следва:
Появява
се следната диаграма:
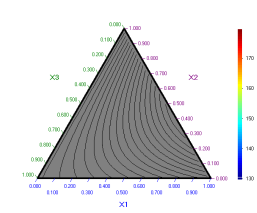
Фактът,
че цялото поле е сиво означава, че при
X4
= 0 няма състави, които да удовлетворяват всички изисквания, поставени с
ограниченията.
По
подобен начин могат да се начертаят и други сечения на повърхнината. За да
стане това се обявяват променливите, които ще излязат на графиката, а на
останалите се задават номинални стойности, както беше показно по-горе. Например,
ако се зададе
X3 = 0 се получава следната
симплексна диаграма:
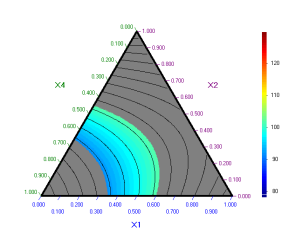
За
да се получат най-добрите възможни резултати е необходима оптимизация.
Начало
Обратно
към въвеждане на данни
Оптимизация
Оптимизацията
се извършва както при задачите с независими променливи. В примера ще търсим
минимум на изтриваемостта, при ограничения дефинирани с неравенства най-отдолу
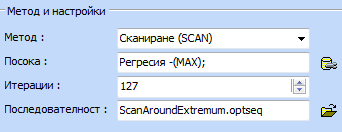
в моделите. Методите за оптимизация при смеси са два: случайно търсене или
сканиране. Може да се използва също и последователност
ScanAroundExtremum.optseq.
В
случая ще използваме сканирането и посочената последователност. Към
оптимизацията може да се влезе или от контурните диаграми, като се кликне
бутона  или се избира
или се избира
 .
Появяват
се настройките за оптимизацията от които избираме метод, посока на търсене и
ако желаем – последователност от оптимизационни алгоритми:
.
Появяват
се настройките за оптимизацията от които избираме метод, посока на търсене и
ако желаем – последователност от оптимизационни алгоритми:
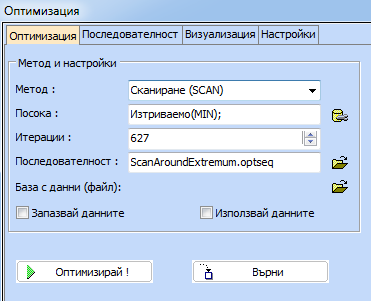
Кликва
се „Оптимизирай“, изчаква се да се получи решението и след това се кликва
бутона „Върни“. При това оптималните стойности на компонентите се появяват на
екрана в близост до графиката:
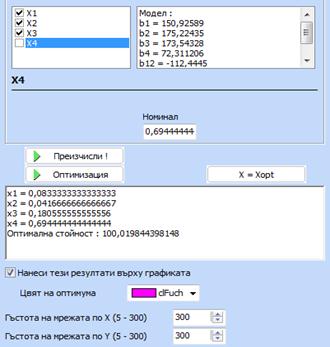
Ако се кликне
X=Xopt
оптималната
точка се появява и на графиката (при х4=0,694) :
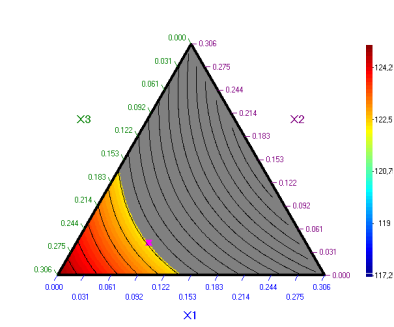
Могат
да се начертаят и други сечения (при други фиксирани стойности на някой от
факторите). Например при фиксирана стойност на х3 = 0,1806
се получава графиката:
Начало
Обратно
към въвеждане на данни
Анализ
на експерименти със смеси при двустранни ограничения на компонентите на сместа
В
тази задача обикновено броят на опитите е по-голям от броя на коефициентите в
регресията и не се налага да се правят допълнителни „контролни опити“.
Особеностите в тази задача са следните:
-
Както
при всички експерименти със смеси трябва да се използват приведени
полиномни модели (без свободен член и без втори или по-високи степени на
компонентите)
-
 Ограниченията
на компонентите водят до непълно използване на пространството, което се
отразява на това, че диаграмите се чертаят само в част от симплексното
пространство
Ограниченията
на компонентите водят до непълно използване на пространството, което се
отразява на това, че диаграмите се чертаят само в част от симплексното
пространство
Пример.
Изследва се яркостта на светене у (в свещи) на смес с
компоненти: магнезий ( x1 ), натриев нитрат ( x2 ), стронциев нитрат ( x3 )
и свързващо вещесто ( x4 ). Наложени са следните ограничения на компонентите:
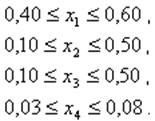
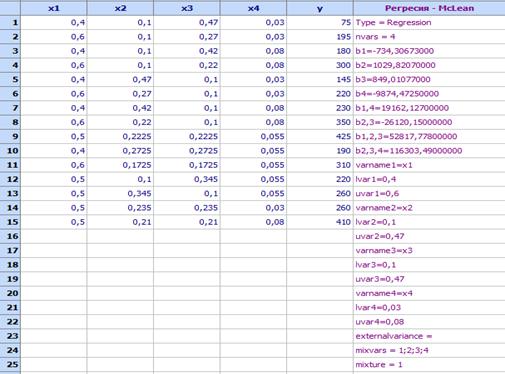
Използван
е план с двустранни ограничения на компонентите (McLean
& Andersоn),
който заедно с резултатите от експеримента е даден в следната таблица (файл
Mixtures-Pseudo-McLean.qsl
- от директорията Primeri (намира
се в директорията в която е инсталиран продуктът)):
Намерен
е следният регресионен модел:

Той
е пренесен в таблицата и по него се чертаят контурни диаграми. Процедурата за
изчертаване е същата като при симплексните решетки. Програмата сама определя
областта очертана от ограниченията. Кликва се иконката
.
Като
„трета зависима“ е избрана х3. По-долу са дадени две контурни диаграми за
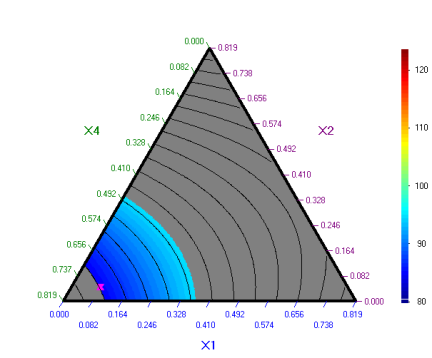
х1,х2,х3 при две различни стойности на х4.
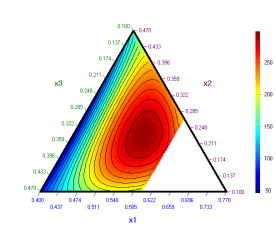
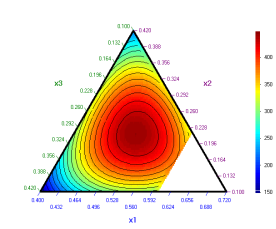
х4 =
0.03 х4 = 0,08
Оптимизационната
задача се дефинира както следва:
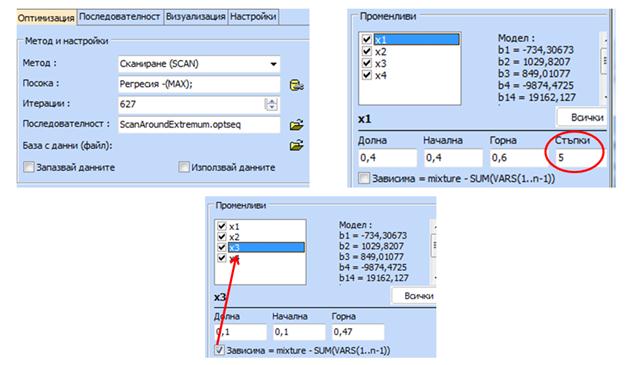
Резултатът
от оптимизацията е:

На следващата графика е нанесена оптималната
точка. Дефинирането на оптимизационната задача е следното:
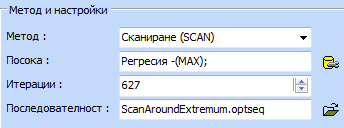
При
тези параметри оптимизацията е повторена два пъти, за да се уточни по-добре
оптимума. Графиката по-долу е получена след кликване върху бутона
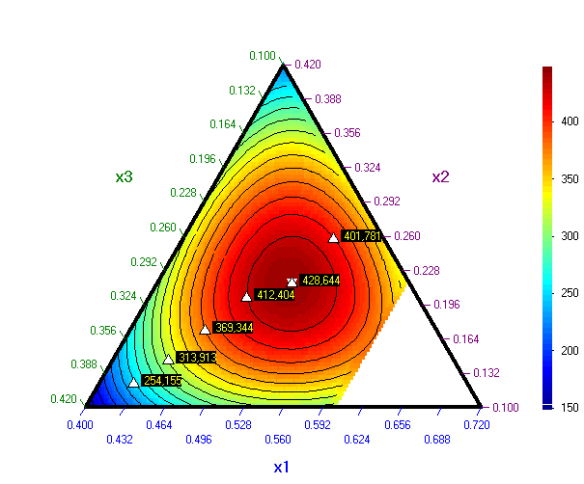
Тази
графика е начертана при х4 = 0,08
Начало
Обратно
към въвеждане на данни
Използване
на псевдокомпоненти при ограничения в симплекса
Ако
на компонентите на сместа са зададени ограничения и ограничената област е също
симплекс, тогава е удобно да се работи с псевдокомпоненти. Псевдокомпонентите
са фиктивни променливи, за които са изпълнени условията за съществуване на
правилен симплекс, независимо че за оригиналните компоненти това не е
изпълнено. Ако псевдокомпонентите са означени с
z1, z2, ...., zq
за
тях са изпълнени условията:
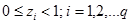
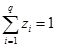
Удобството
идва от това, че ако се работи в псевдокомпоненти могат да се използват планове
на експеримента, предназначени за правилен симплекс, например симплексни
решетки на Шефе или симплекс-центроидни планове. Планът се съставя в
псевдокомпоненти, а след това за да се изпълни се трансформира в оригинални
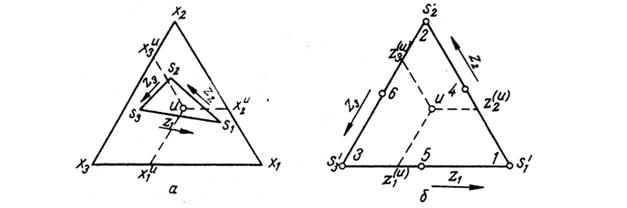
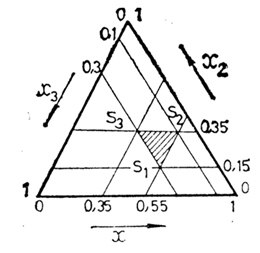
компоненти. По-долу е показана ограничена област в симплекса с върхове
S1,S2,S3,
която в оригинални компоненти (X1,X2,X3)
е разположена произволно (фигура а). След трансформирането в псевдокомпоненти (Z1,Z2,Z3)
тя се превръща в правилен симплекс (фигура б).
Да предположим, че в оригинални компоненти
координатите на върховете на ограничената подобласт са:
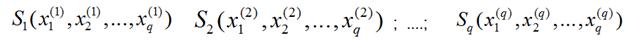
Можем
да запишем някакъв план в псевдокомпоненти, а след това за да се реализира на
практика трябва да се премине в оригинални компоненти. Трансформацията от
псевдокомпоненти в оригинални компоненти става по формулата:
x
= Az,
където
стълбовете на матрицата А са зададени чрез координатите на
върховете в ограничената подобласт:
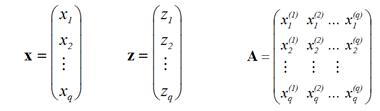
Пример:
Изследва се средното отворено време
y(s)
на топимо лепило за безшевно свързване на листа в полиграфията. Факторите са 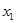 - миравитен,
- миравитен, 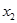 -
пиролен,
-
пиролен, 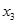 - парафин. Зададени са следните
ограничения на компонентите:
- парафин. Зададени са следните
ограничения на компонентите:
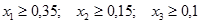
Те определят следните върхове на ограничената
област:
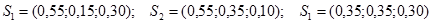
Ако
се използва симплексна решетка в псевдокомпоненти, трансформацията х = Аz
се записва както следва:

Ще
покажем как това се прави с
QstatLab:
1.
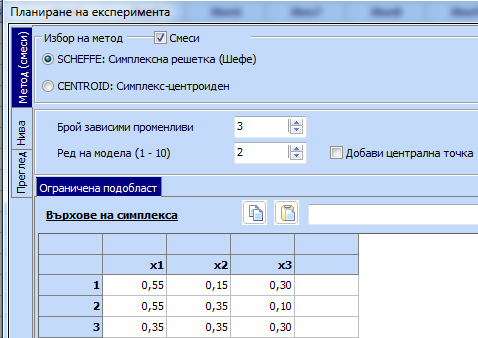
Създава се симплексна решетка на Шефе с програмата
за планиране на експерименти при смеси - иконка
и
след това:
Тук
е маркирано полето пред „Смеси“, избрана е симплексна решетка на Шефе, зададени
са броят на компонентите (3) и реда на модела (2) и са въведени върховете на
ограничената подобласт. Като се кликне „Преглед“ и „Старт“ се получава следният
план на експеримента:
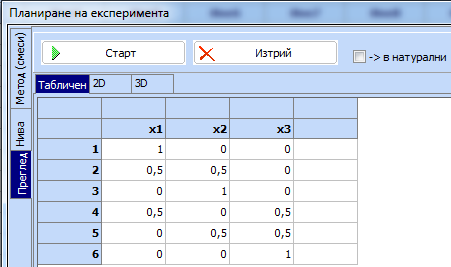
Този
план е записан в псевдокомпоненти. Той може да се пренесе в основната таблица
на програмата с бутона  .
За да го видим
в оригиналните компоненти (което е важно за изпълнение
на опитите) маркираме полето пред надписа „в натурални“ и се получава следният
план в натурални променливи. При това се сменя надписът пред маркираното поле и
става „в псевдокомпоненти“, за да се използва, ако искаме да видим отново плана
в псевдокомпоненти. Получава се следният план, който също може да се пренесе в
основната таблица:
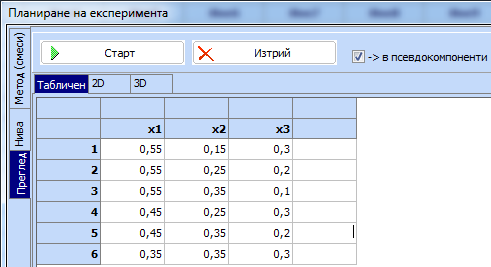
.
За да го видим
в оригиналните компоненти (което е важно за изпълнение
на опитите) маркираме полето пред надписа „в натурални“ и се получава следният
план в натурални променливи. При това се сменя надписът пред маркираното поле и
става „в псевдокомпоненти“, за да се използва, ако искаме да видим отново плана
в псевдокомпоненти. Получава се следният план, който също може да се пренесе в
основната таблица:
Ако
по получения план се изпълнят опитите и се запишат в таблицата става възможно
да се построи модел и да се начертаят контурни диаграми. Нека данните да са
както в таблицата по-долу:
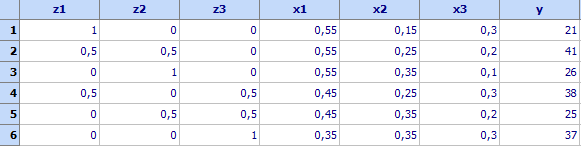
С
помощта на програмата за регресионен анализ (за смеси) може да се получат
модели както в псевдокомпоненти, така и в оригинални компоненти. Моделът в
псевдокомпоненти е:
y =
21z1+41z2+26z3+28z1z2+14z2z3+6z1z3
В
QstatLab
моделът
се записва така:

Контурната
диаграма, начертана с помощта на модела в псевдокомпоненти е:
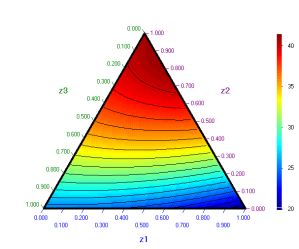
Ще
намерим мaксимум на отвореното време у
с помощта на сканиране и използване на оптималната последователност
ScanAroundExtremum.optseq.
Искаме максимумът да се получи както в псевдокомпоненти, така и в
псевдокомпоненти. Най-напред в произволни свободни клетки се записват
координатите на върховете на органичената подобласт (в случая това са колони
P,Q,R):
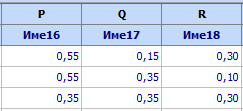
Накрая на модела в псевдокомпоненти се
добавят следните редове:
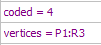
С
тях програмата се инструктира, че моделът е изведен в псевдокомпоненти и се
задават координатите на върховете на ограничената подобласт. Моделът придобива
следният вид:

Ако
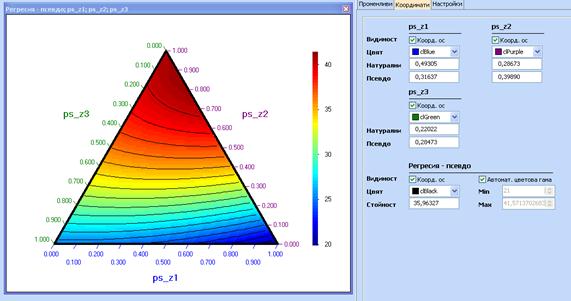
сега начертаем контурната диаграма и движим курсора по нея, координатите на
курсора ще се появяват както в псевдокомпоненти, така и в натурални компоненти:
След
като се начертае контурната диаграма се кликва бутона
и се
правят следните настройки:
Оптималният
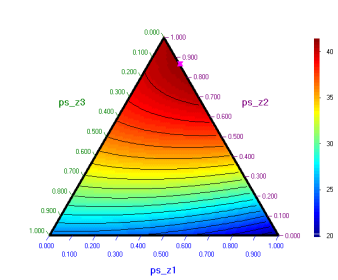
резултат се получава както в псевдокомпоненти, така и в оригинални компоненти:

Резултатът
може да бъде нанесен на графиката с псевдокомпоненти:
Втори начин за оптимизация:
използване на модел в оригинални компоненти
С помощта на програмата за
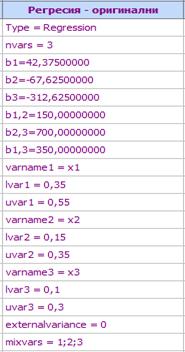
регресионен анализ може да се изведе модел в оригинални компоненти. За примера
той е следният:
y =
42,375x1-67,625x2-312,625x3+150x1x2+700x2x3+350x1x3
Той се записва както следва:
С
бутона  може да се начертае
графика, а след това да се кликне „Оптимизация“. Настройките за оптимизацията
са същите както по-горе. Получава се следното оптимално решение.
може да се начертае
графика, а след това да се кликне „Оптимизация“. Настройките за оптимизацията
са същите както по-горе. Получава се следното оптимално решение.

След
нанасянето на графиката на оптималната точка се получава следното:
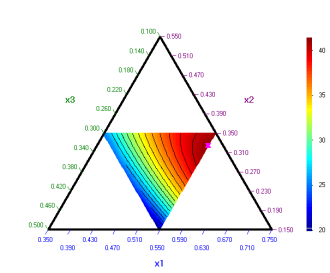
Резултатът
е същият както този получен чрез модел в псевдокомпоненти, но графиката е в
оригиналните променливи.
Начало
Обратно
към въвеждане на данни
Планиране
и анализ на експерименти със смеси с едновременно участие на компоненти на
сместа и независими променливи
В
тази задача има два вида фактори:
·
Компоненти на сместа. Да предположим, че има
q
компоненти
на сместа. За тях са валидни условията:
0 <= xi <= 1, i = 1, 2, ... , q (1)
и
(2)
Условието
(2) прави компонентите на сместа линейно зависими.
·
Променливи на процеса. Те са линейно
независими и за тях не е приложимо условието (2). Ако броят на тези
променливи е r
то
те се изменят в границите:
-1 < xi < 1, i
= q+1, q+2, ..., m (3)
Общият брой на факторите е:
m = q+r
Модели, когато в модела има линейно зависими (1)
и (2) и линейно независими (3) променливи
Ако предположим, че в модела
има q компоненти на сместа и
r
линейно
незавсисими фактора (т.е. общият брой фактори е
m=q+r),
то са възможни следните приведени модели:
- Линеен
модел с взаимодействия:
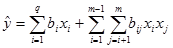
(4)
В този модел липсват
свободен член и линейните членове на независимите фактори, има всички
взаимодействия между зависимите и независимите фактори.
·
Полином от втора степен:
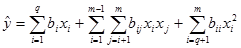 (5)
(5)
Този
модел се различава от (4) по това, че към него са добавени вторите степени само
на линейно независимите променливи (няма втори степени за линейно зависимите).
Планиране
на експеримента за смеси с линейно зависими и независими фактори
Използва
се следната процедура:
1.
Комбинират се план за независими фактори
(променливи на процеса) със симплексна решетка или някой от другите планове за
смеси (може и с ограничения - Мак-Лийн
и Андерсън
или псевдокомпоненти). Например, ако
имаме три линейно зависими фактора (компоненти на сместа) -
x1, x2, x3 и две независими променливи -
x4, x5 комбинираният (кръстосаният) план
може да се представи графично по следния начин:
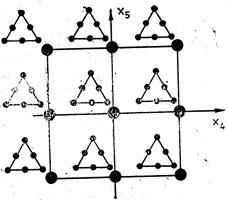
Този
план ще има 6х9 = 54 опита.
2.
Тъй като броят на комбинациите обикновено
става прекалено голям след това се пуска процедурата за генериране на
D-оптимални
планове, като точките на плана се търсят само между т.н. „кандидат-точки“. Това
са точки с координатите на комбинациите съставени както е показано по-горе.
Задава се определен брой опити и се спира когато той се достигне.
При
генерирането на такива планове е добре да се знае колко е броят на
коефициентите на регресията в модела
k.
Обикновено планът трябва да има няколко опита повече от броя на коефициентите,
за да се получи възможност да се проверява адекватността на модела
Пример.
Да предположим, че желаем да генерираме план на
експеримента от втори ред за смес с 3 линейно зависими фактора (q
=3) и два линейно незавсисими (r =
2). Построяването става по следния начин:
1.
Извиква се програмата за генериране на
планове с иконката 
2.
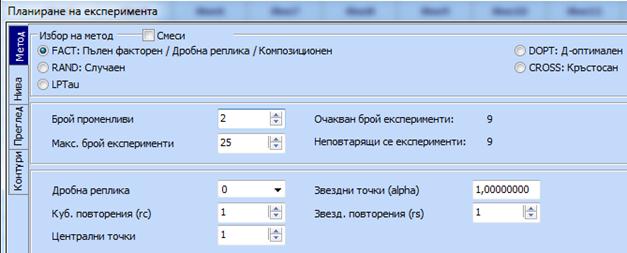
Правят се настройки за построяване на
оптимален композиционен план за 2 независими променливи. Той ще има 9 точки:
3.
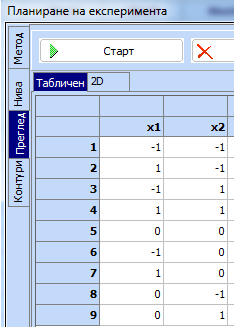
Кликва
се „Преглед“ и след това „Старт“ и се построява плана:
4.
Копира се плана в клипборда
5.
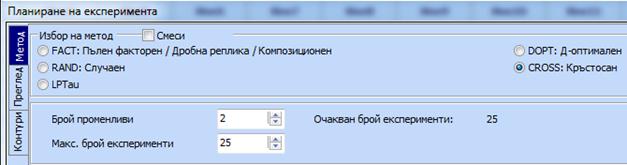
Кликва
се бутона „Метод“ и след това се маркира
CROSS:
Кръстосан:
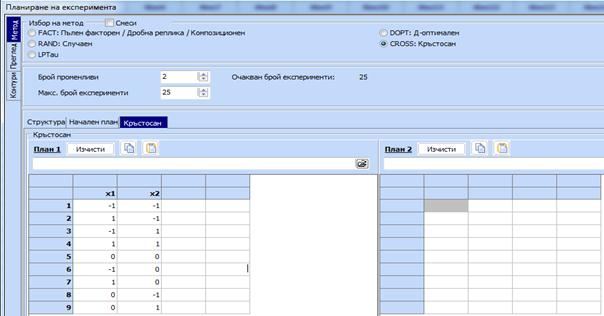
6.
Нанася се от клипборда запомнения план за
кубична област с 2 фактора в полето наречено План 1.
7.
Маркира се полето „Смеси“ и след това „SCHEFFE:
Симплексна решетка (Шефе)“

8.
Отива
се на „Преглед“, след това на „Старт“ и се генерира симплексна решетка на Шефе
за 3 компоненти от втори ред с добавена средна точка:
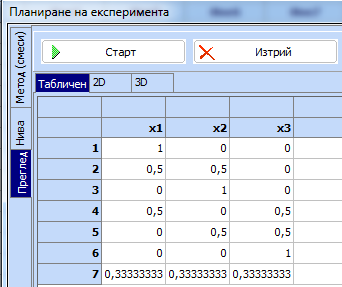
9.
Копира се в клипборда получената симплексна
решетка
10.
Връщаме се на „Метод“ и се появява таблицата с
маркирано CROSS. Нанасяме от
клипборда симплексната решетка в полето наречено „План 2“:
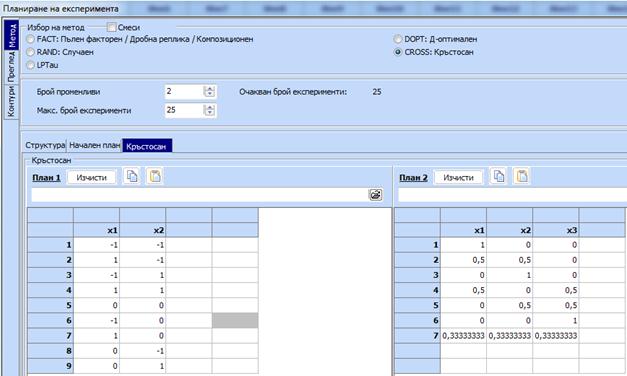
11.
Кликваме
бутона „Преглед“, след това „Старт“ и получаваме комбинираният план с 7 х 9 =
63 опита. Фрагмент от него е показан на следващата фигура:
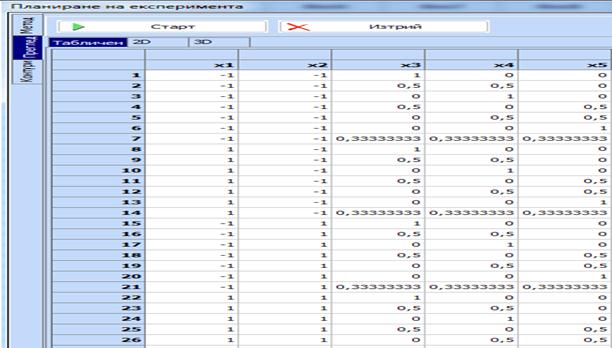
12.
Преместваме плана в основната таблица чрез
кликване на бутона
По
подобен начин можем да комбинираме какъвто и да е план за независими променливи
с план за компоненти на сместа (симплексни решетки на Шефе, симплекс-центроидни
планове, планове с ограничения на компонентите (EXTVERT),
случайни точки в симплекса (RANDMIX).
Плановете, които ще се комбинират могат да бъдат зададени в кодирани или
натурални променливи (по избор на потребителя).
Начало
Обратно
към въвеждане на данни
Избор
на план със зададен брой опити от зададени „кандидат-точки“ с процедурата за
генериране на D-оптимални
планове
Кръстосването
на планове за линейно зависисми и независими фактори обикновено води до
прекалено голям брой опити. Той може да се намали с използване на процедурата
за генериране на
D-оптимални планове от
зададени „кандидат-точки“
Пример.
Ако линейно зависимите фактори са
q
= 3, а независимите са
r = 2
броят на опитите в кръстосания план е 63. Той беше построен в предишния пример.
От друга страна модел от втори ред за същата задача ще има 15 коефициента:
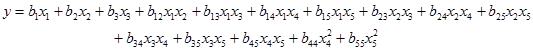
За
оценяването на
k = 15 коефициента не
са нужни N=63 опита, това може да
стане с няколко опита повече от броя на коефициентите. Да предположим, че
потребителят иска да генерира план за този случай с 20 опита. Тогава той ще има
на разположение
N-k
=
20 – 15 = 5 степени на свобода за статистически анализ на модела. За избор на
20 от всичките 63 опита може да се използва процедурата за генериране на
D-оптимални
планове от зададени „кандидат-точки“. Тя е следната:
1.
Генерира се кръстосан план с 63 опита. Това
беше показано в предишния пример за
q
= 3 и r = 2
2.
Копира се генерирания план в клипборда (за
примера той има 63 точки)
3.
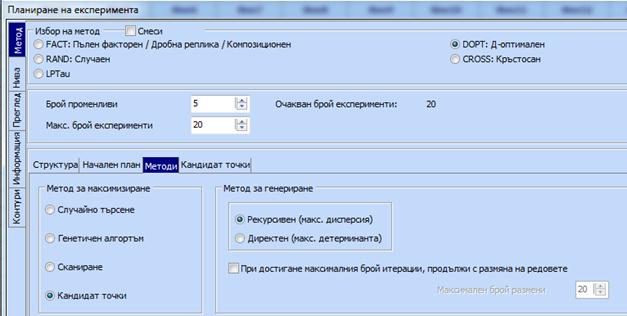
Отива се на „Метод“ и се правят следните
настройки:
-
Маркира
се полето
DOPT:
Д-оптимален
-
Нанасят
се от клавиатурата „Брой променливи = 5“ и „Макс.брой експерименти = 20“
-
Кликва
се бутона „Методи“ и се маркира „Кандидат-точки“
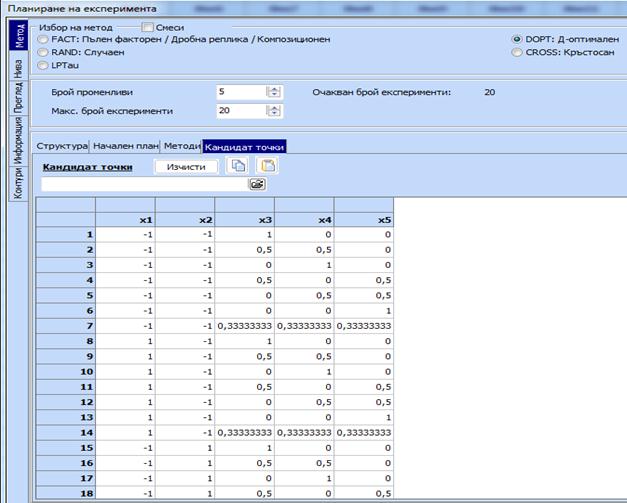
4.
Кликва
се бутона „Кандидат-точки“ и в отворилото се поле се нанася от клипборда
предварително запомненият кръстосан план. Маркира се също надписа
DOPT:
Д-оптимален:
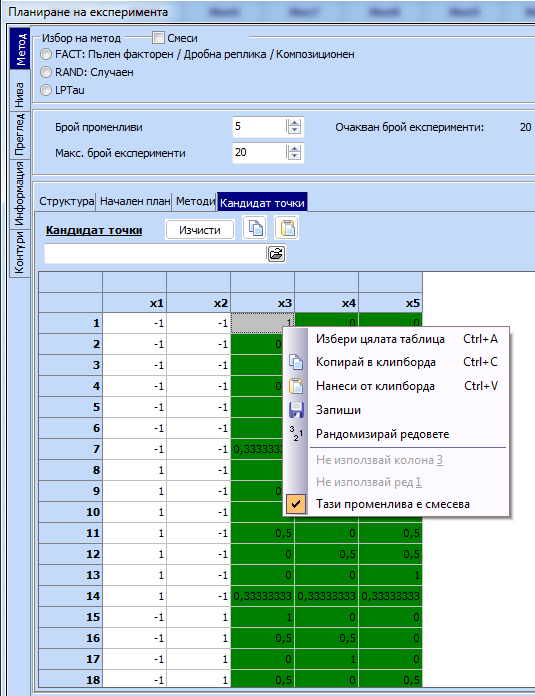
5.
Курсорът се поставя последователно върху
колоните, където са разположени смесевите променливи (линейно зависимите) и се
кликва с десен бутон на мишката. Появява се меню, от което трябва да изберем
надписа „Тази променлива е смесева“.
Mаркираните
по този начин колони се оцветяват в зелено и ще бъдат разглеждани от компютъра
като линейно зависими.
6.
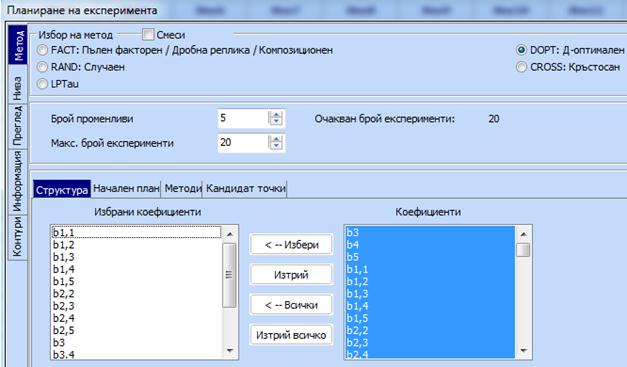
Кликва се бутона „Структура“ и се маркират
всички коефициенти на избрания от нас модел в дясното поле, наречено
„Коефициенти“. В нашия пример това са коефициентите на модел от втори ред за
линейно зависими и независими коефициенти. Те се прехвърлят със стрелката  в
лявото поле наречено „Избрани коефициенти“:
в
лявото поле наречено „Избрани коефициенти“:
7.
Кликва
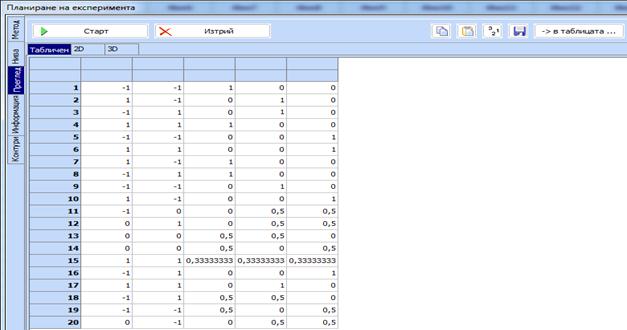
се „Преглед“, след това „Старт“ и се получава план с 20 точки, избрани измежду 63
кандидат-точки по критерия
D-оптималност.
Този план може да се прехвърли в основната таблица за използване, като се
кликне бутона „в таблицата“
Начало
Обратно
към въвеждане на данни
Регресионен анализ, графична интерпретация и
оптимизация при задачи за изследване на свойствата на смеси с линейно завсисими
и независими фактори
Регресионният анализ и
графичната интерпретация са същите както при другите планове, с изключение на
случая когато за ограничената област са използвани псевдокомпоненти. Ще
илюстрираме това с два примера. В първия не се прилагат псевдокомпоненти, във
втория е използвана трансформация в псевдокомпоненти.
Що се отнася до
оптимизацията, при смеси е възможно да се изполват само два метода: сканиране
или случайно търсене.
Пример 1 (без
псевдокомпоненти).
Изследва се якостта на натиск на бетон
на 28 ден от създаването му (y,
MPa).
При експеримента са изменяни
три компоненти на смес, сумата на които трябва да е винаги 1:
|
No
|
Компонента
|
Код
|
Части от 1
|
|
|
|
|
Долна
|
Горна
|
|
1
|
Трошен пясък фракция 0/4
|
Z1
|
0.47
|
0.67
|
|
2
|
Трошен камък фр. 4/16
|
Z2
|
0.105
|
0.305
|
|
3
|
Трошен камък фр. 16/32
|
Z3
|
0.125
|
0.325
|
За единица е приета
стойността 1000
kg. Освен това е
изменяно количеството цимент което варира независимо в границите от 300 до 400
kg.
Ще разглеждаме цимента като независима променлива, която в кодиран мащаб се
изменя в границите 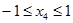 и приема само граничните си
стойности (-1 и 1). В състава има още вода, която е винаги в постоянно количество
равно на 200 kg. Затова водата не се
включва в модела.
и приема само граничните си
стойности (-1 и 1). В състава има още вода, която е винаги в постоянно количество
равно на 200 kg. Затова водата не се
включва в модела.
Ще решим задачата по следния
начин:
-
Ще съставим план на
експеримента за зависимите променливи, като използваме програмата
EXTVERT
-
Ще съставим кръстосан
план
-
След изпълнение на
опитите ще построим регресионен модел
-
Ще намерим състав,
който осигурява максимум на якостта
-
Ще начертаем линии на
постоянни стойности
Започваме със съставяне на
план на експеримента.
1.
Избираме иконката
 и
правим следните настройки:
и
правим следните настройки:

2.
Задаваме границите на ограничената подобласт:
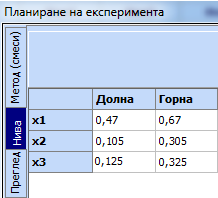
3.
Кликваме “Преглед“, след това „Старт“,
получаваме плана.
Рандомизираме го с бутона
 и го прехвърляме в основната
таблица
и го прехвърляме в основната
таблица
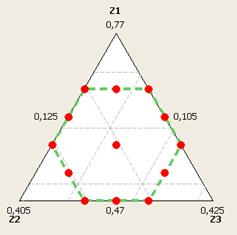
Графично
този план изглежда така:
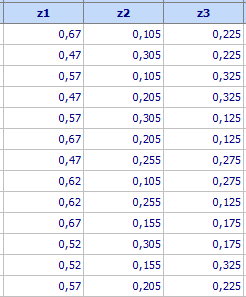
4.
В случая кръстосването се състои в повтаряне
на този план два пъти – един път при
X4
= -1 и втори път – при Х4 = 1. Планът по смесевите променливи е рандомизиран,
т.е. редовете в горната таблица са разместени по случаен начин. Така е получен
следният план на експеримента (файл
Mixtures-Beton.qsl
- от директорията Primeri (намира
се в директорията в която е инсталиран продуктът)):
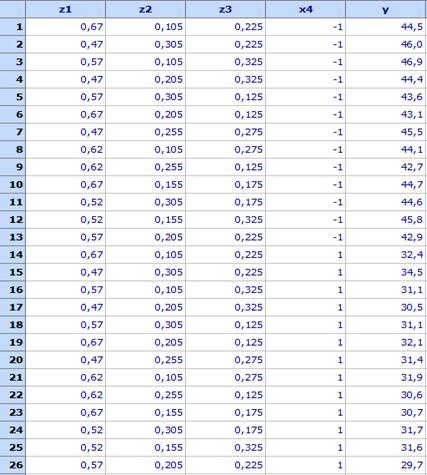
В последната колона са дадени
резултатите от опитите.
5.
Извиква се програмата за регресионен анализ и
се правят следните настройки:
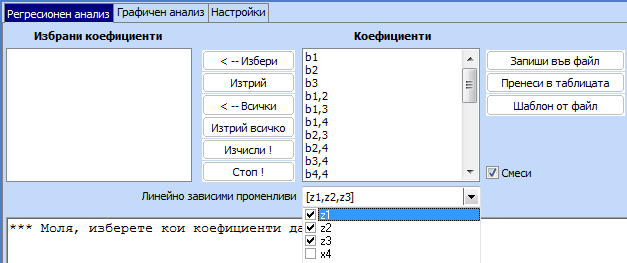
6.
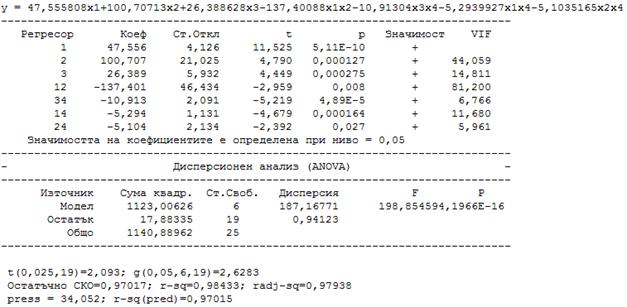
Избира се модел от втори ред и се получава:

Изчистваме последователно
коефициентите, които създават силна мултиколинеарност (много голями стойности
на VIF). Това са
b13
и след това b23.
Получава се следният модел:
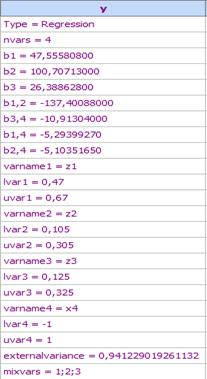
7.
Пренасяме модела в основната таблица:
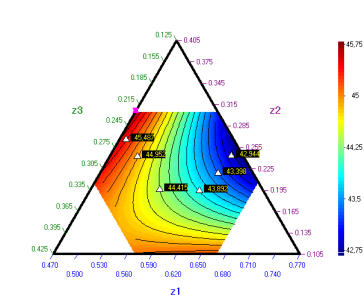
8.
Използваме модела за построяване на графика и
извършване на оптимизация. Оптималният състав е:

Начало
Пример 2. (с
псевдокомпоненти)
Изследва се модулът при 300 %,
y
(kg/cm2)
на каучукови смеси за диафрагми на автомобилни гуми. В изследването участват
три линейно зависими фактора: естествен каучук (х1), стандартен малайзийски
каучук SMR (х2) и
бутадиенстиролов каучук БСК (х3). За поевтиняване на рецептурата е наложено
следното условие: х3 > 0,5. Освен това в изследването са включени и три
независими фактора: масло (х4), пиролен (х5) и сантокюр
MOR
(х6). За независимите фактори са приети следните интервали на вариране (всички
променливи се измерват в масови части (м.ч)):
|
|
Масло (м.ч.)
|
Пиролен (м.ч)
|
Сантокюр (м.ч.)
|
|
Основно ниво
(xi = 0)
|
3
|
8
|
1,3
|
|
Интервал на вариране
|
3
|
3
|
0,3
|
|
Горно ниво
|
6
|
11
|
1,6
|
|
Долно ниво
|
0
|
5
|
1,0
|
Ограничението х3 > 0,5
определя симплексна подобласт:
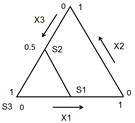
Върховете на ограничената
подобласт са с координати:
S1
(0,5; 0; 0,5),
S2 (0; 0,5 , 0,5) и
S3
(0; 0; 1). Затова за зависимите променливи са използвани псевдокомпоненти.
Планът и резултатите от наблюденията са дадени във файл
Mixtures-Process_variables.qsl
от
директорията Primeri (намира се в директорията в
която е инсталиран продуктът) и са показани в следната
таблица:
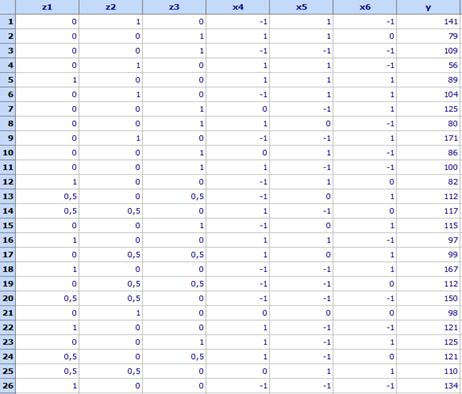
Линейно зависимите фактори
са записани в колони
A,
B,
C
чрез
псевдокомпоненти. Показателят „Модул при 300 %“ (у) е в колона
G.
За построяване на модел с
псевдокомпоненти е използван регресионен анализ, който за смеси има следните
особености:
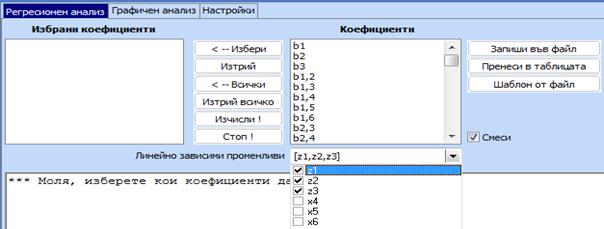
1.
Избира
се иконката за регресионен анализ
 и се маркира полето “Смеси“.
Освен това чрез падащото меню се посочва кои променливи са линейно зависими:
и се маркира полето “Смеси“.
Освен това чрез падащото меню се посочва кои променливи са линейно зависими:
Моделът
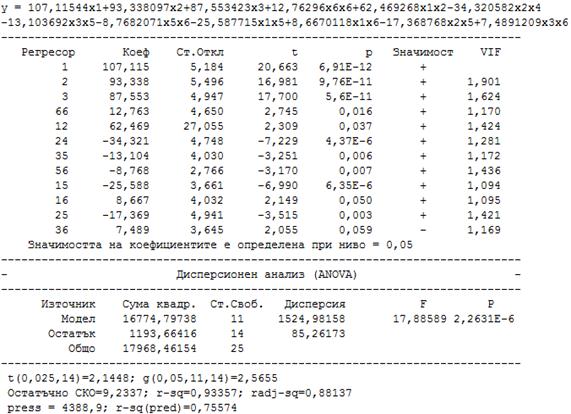
се оказва с твърде много незначими коефициенти:
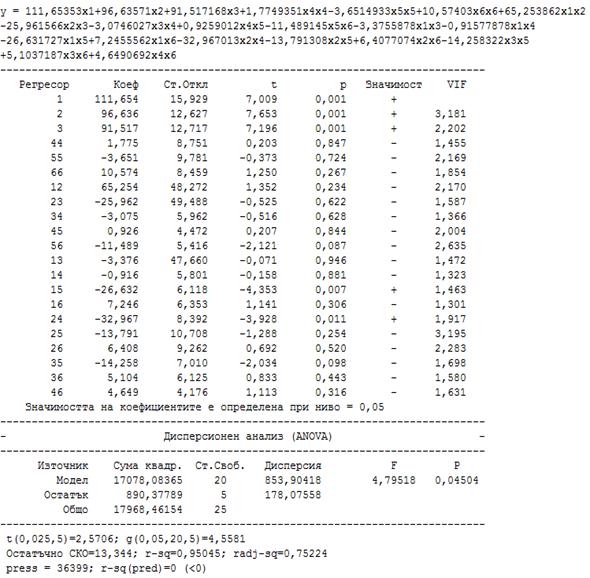
Неговите свойства се
подобряват, ако се елиминират незначимите коефициенти:
Ако искаме да получим
резултатите и в натурални променливи, добавяме към модела следните редове:
Получава се модел, който в
QstatLab
изглежда
така:
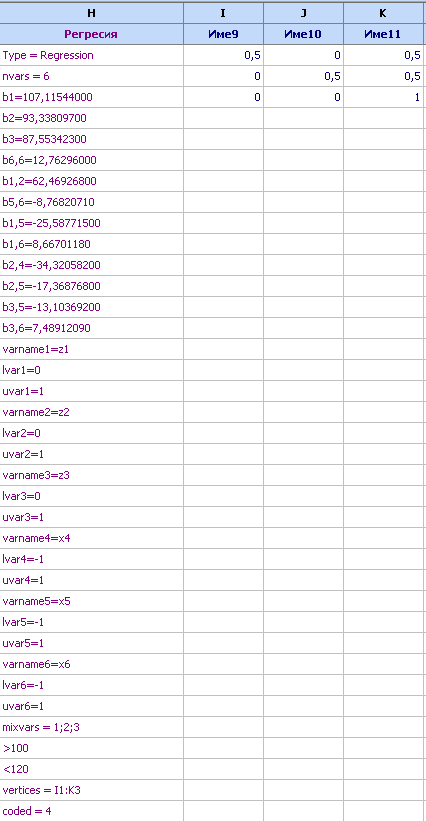
Редът
vertices
= I1:K3
инструктира програмата, че oт I1 до
K3
са записани координатите на върховете на ограничената подобласт. Това се
използва при оптимизацията и в графиката за изчисляване на координатите на
точките в натурален мащаб. Това позволява графиката да се представи в натурални
променливи.
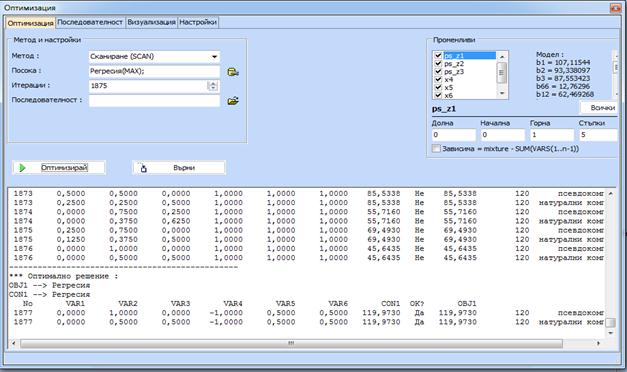
Ако се кликне „Оптимизация и
се направят настройките, показани по долу се получава оптималният режим:
Симплексната
диаграма с нанесения на нея оптимален режим изглежда така:
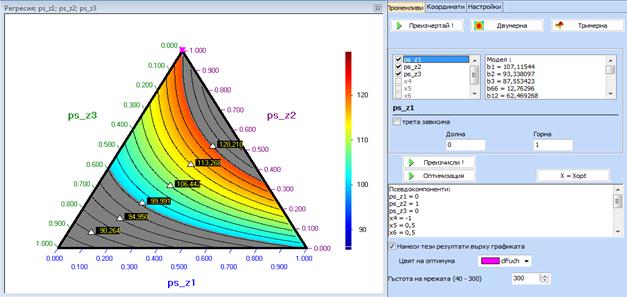
Стойоностите на натуралните
и псевдокомпонентите могат да се проследят в раздела ‚Координати‘:
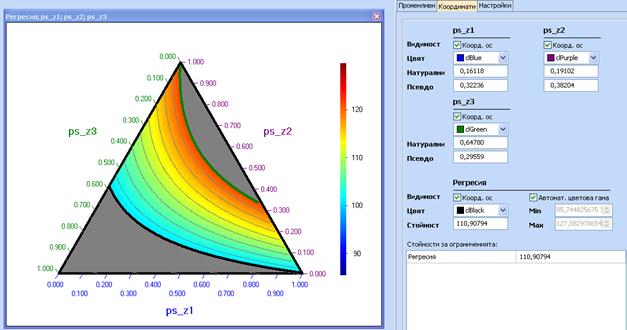
Ако се кликне бутона
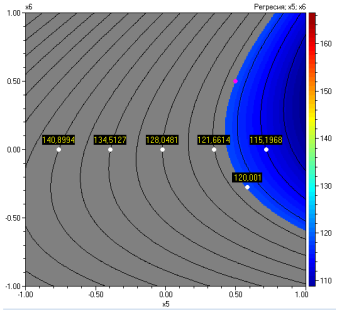
„Двумерна“ могат да се начертаят и двумерни диаграми по отношение на
независимите променливи. Те ще бъдат построени при оптималните стойности на
всички променливи, ако се кликне и бутона “X
= Xopt”. Диаграмите са показани
по-долу:
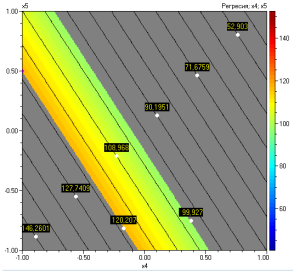
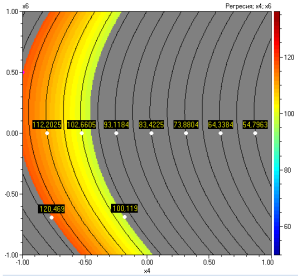
Начало
Обратно
към въвеждане на данни